
小红书如何收集大数据
 摘要:
收集什么数据?(数据维度)小红书收集的数据远不止用户在App上看到的表面内容,而是构建了一个多维度的用户画像和内容生态数据库,主要可以分为以下几类:用户行为数据这是最核心、最基础的...
摘要:
收集什么数据?(数据维度)小红书收集的数据远不止用户在App上看到的表面内容,而是构建了一个多维度的用户画像和内容生态数据库,主要可以分为以下几类:用户行为数据这是最核心、最基础的... 收集什么数据?(数据维度)
小红书收集的数据远不止用户在App上看到的表面内容,而是构建了一个多维度的用户画像和内容生态数据库,主要可以分为以下几类:
(图片来源网络,侵删)
用户行为数据
这是最核心、最基础的数据,直接反映了用户的兴趣和偏好。
- 显性行为:
- 搜索记录: 用户搜了什么词?这直接反映了其当下的需求。
- 浏览行为: 在哪个页面停留了多久?是快速划过还是仔细阅读?对哪些笔记类型(图文/视频)更感兴趣?
- 互动行为: 点赞、收藏、评论、分享,收藏 > 评论 > 点赞 > 分享,这个权重序列代表了用户对内容的认可度,分享是最高级别的认可。
- 关注行为: 关注了哪些博主?这些博主的标签是什么(美妆、穿搭、母婴、旅游)?
- 发布行为: 发布了什么类型的笔记?使用了哪些标签?@了哪些人?
- 隐性行为:
- 点击路径: 用户进入App后的操作流程,首页推荐 -> 搜索 -> 点击某个笔记 -> 进入该博主主页 -> 关注。
- 不感兴趣操作: 用户主动点击“不感兴趣”或“减少此类推荐”,这是非常强的负反馈信号。
- 跳出率: 用户点击一个笔记后,在几秒内就退出了,说明内容可能没有满足其预期。
用户属性数据
这是构建用户画像的基础,帮助平台理解“用户是谁”。
- 注册信息: 手机号、第三方账号授权(微信、微博等)、性别、年龄(部分需完善)。
- 设备信息: 手机型号、操作系统(iOS/Android)、网络环境(Wi-Fi/4G/5G)。
- 地理位置: 用户常出现的城市、区域,这对于本地生活服务(如探店)的推荐至关重要。
- 兴趣标签: 通过算法分析用户的行为数据,自动为其打上的标签,如“成分党”、“极简主义”、“咖啡爱好者”、“新手妈妈”等。
内容数据
这是平台的核心资产,所有数据都围绕内容展开。
- 笔记元数据: 标题、正文、标签、发布时间、发布者ID。
- 内容特征数据:
- 文本: 使用了哪些关键词?情感倾向是正面、负面还是中性?
- 图像/视频: 通过AI图像识别技术,分析图片中的颜色、风格、物体(如口红、包包、风景)、场景(如厨房、办公室)、品牌Logo等,视频还会分析其时长、帧率、BGM等信息。
- 互动数据: 笔记的点赞、收藏、评论、分享数量,以及评论的情感分析。
- 创作者数据:
- 博主画像: 粉丝数、粉丝画像(年龄、性别、地域分布)、笔记平均互动率、垂直领域、商业合作历史等。
- 账号健康度: 内容更新频率、违规记录、粉丝增长/流失情况。
商业与交易数据
这是小红书商业化闭环的关键数据。
(图片来源网络,侵删)
- 搜索电商词: 用户搜索并最终购买了哪些商品?搜索“小棕瓶”后购买了哪款产品。
- 种草转化路径: 用户从看到一篇“种草”笔记,到点击商品链接,再到最终下单支付的完整路径。
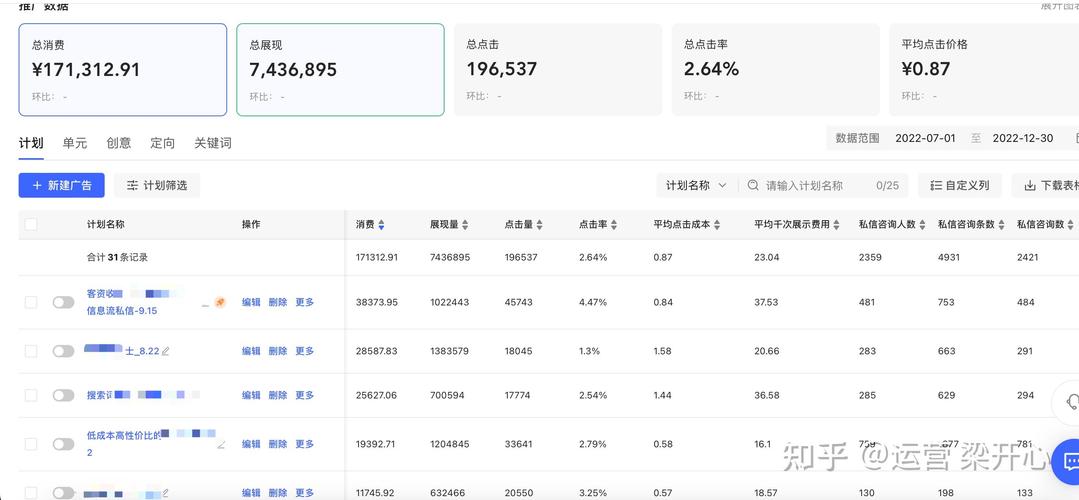
- 广告数据: 广告的曝光量、点击率、转化率、互动成本等,用于评估广告效果和优化投放策略。
如何收集数据?(技术与方法)
小红书通过多种技术和渠道,高效、合规地收集上述数据。
前端埋点
这是收集用户行为数据最主要的方式,开发者在App的各个功能点(如点击按钮、进入页面、滑动屏幕等)预先埋入一小段代码。
- 工作原理: 当用户触发某个行为时,代码会自动记录下事件信息(如事件类型、时间戳、用户ID、页面信息等),并打包发送到后端服务器。
- 优点: 可以精细追踪到用户在App内的每一个微观操作,数据颗粒度非常细。
后端日志
当用户进行某些操作时,服务器端会自动生成日志文件。
- 应用场景: 服务器处理请求(如登录、发布笔记)、数据库操作记录、错误日志等,这些数据反映了系统的运行状态和用户的核心操作。
- 优点: 数据更稳定,不易被前端技术手段干扰,适合做宏观分析。
机器学习与AI分析
这是将原始数据转化为有价值信息的关键步骤。
(图片来源网络,侵删)
- 自然语言处理: 分析笔记标题、正文和评论,提取关键词、识别情感、理解用户意图(用户搜索“适合敏感肌的粉底液”,NLP能理解其核心需求是“敏感肌”和“粉底液”)。
- 计算机视觉: 自动识别图片和视频中的内容,为内容打上视觉标签,识别出这是一张“日系妆容”、“红色连衣裙”、“在咖啡店”的照片,这是小红书“以图搜图”功能的基础。
- 推荐算法: 基于协同过滤、内容推荐等算法模型,综合分析用户、内容和场景数据,预测用户可能感兴趣的笔记。
用户授权与隐私政策
数据收集必须在合法合规的框架下进行。
- 隐私政策: 用户在注册和使用App时,会同意一份详细的隐私政策,告知用户平台会收集哪些数据、为何收集以及如何使用。
- 权限申请: App会向用户申请手机权限,如位置信息、相册、通讯录等,用户可以选择“允许”或“拒绝”,平台会根据用户授权的范围来获取数据,只有允许位置权限,平台才能获取用户的实时地理位置。
收集到的数据如何应用?(价值闭环)
收集数据不是最终目的,利用数据创造价值才是,小红书的数据应用贯穿其整个业务生态。
核心应用:个性化推荐(信息流)
这是用户最直观的感受,也是大数据最核心的应用。
- 工作流程: 用户打开App -> 算法引擎瞬间调用该用户的画像数据(兴趣、历史行为)和实时场景数据(时间、地点) -> 匹配内容库中的所有笔记 -> 通过复杂的排序模型(考虑相关性、时效性、热度、多样性等) -> 生成一条独一无二的“为你推荐”信息流。
- 目标: 提升用户粘性和使用时长,让用户“刷到停不下来”。
内容生态治理
- 内容审核: 利用AI识别和人工审核相结合,自动过滤色情、暴力、广告、虚假信息等违规内容,维护社区氛围,NLP和CV技术在此扮演重要角色。
- 热点发现: 通过分析大量用户的搜索和互动数据,平台可以快速识别出新兴的热门话题、趋势和产品(如“多巴胺穿搭”、“白开水妆容”),并对其进行流量扶持。
商业变现
- 广告精准投放: 品牌方希望将广告推送给最有可能转化的用户,小红书可以根据其数据库,为品牌精准定位目标人群(如“25-30岁,生活在上海,近期有购买防晒霜意向的女性”),实现广告的高效触达。
- 电商闭环(自营与第三方): 通过分析用户的种草行为和购买数据,优化“小红书小店”或第三方电商平台的商品推荐,提升转化率。
- 品牌合作平台(蒲公英): 为品牌和博主提供匹配服务,平台根据品牌的需求(如预算、目标人群、内容风格)和博主的画像(粉丝质量、垂直领域、报价),智能推荐最合适的合作博主。
产品优化与迭代
- 功能迭代: 通过分析用户的行为数据,发现现有功能的痛点(某个按钮点击率极低,或某个页面跳出率很高),从而指导产品经理进行优化和功能迭代。
- A/B测试: 推出一个新功能(如新的首页布局)时,会将其推送给一小部分用户(A组),并与使用旧版本的用户(B组)进行数据对比,看哪个版本的体验更好(如留存率、互动率更高),再决定是否全量上线。
小红书的大数据收集是一个“前端埋点 + 后端日志 + AI智能分析 + 用户授权”四位一体的系统,它像一个巨大的“数据消化系统”,将用户产生的每一个行为、每一篇内容都作为“食材”,通过算法这个“厨师”进行深度加工,最终烹饪出三大“菜肴”:
- 给用户的: 个性化的信息流和内容。
- 给博主的: 精准的流量增长和商业变现机会。
- 给品牌的: 高效的营销和转化渠道。
这个数据驱动的闭环,是小书书能够从一个简单的“购物笔记分享社区”成长为如今“生活方式入口”和“国民级种草平台”的核心引擎,随着数据隐私法规的日益严格,如何在数据利用和用户隐私保护之间找到平衡,也是小红书持续面临的重要课题。
文章版权及转载声明
作者:99ANYc3cd6本文地址:https://www.chumoping.net/post/6281.html发布于 01-03
文章转载或复制请以超链接形式并注明出处初梦运营网







