
小红书数据结构化,如何将碎片化内容转化为可挖掘的商业价值?
 摘要:
这不仅仅是一个技术问题,更是一个结合了平台生态、用户行为和商业目标的核心议题,我会从“为什么需要结构化”、“结构化的对象是什么”、“如何进行结构化”以及“结构化的应用场景”四个方面...
摘要:
这不仅仅是一个技术问题,更是一个结合了平台生态、用户行为和商业目标的核心议题,我会从“为什么需要结构化”、“结构化的对象是什么”、“如何进行结构化”以及“结构化的应用场景”四个方面... 这不仅仅是一个技术问题,更是一个结合了平台生态、用户行为和商业目标的核心议题,我会从“为什么需要结构化”、“结构化的对象是什么”、“如何进行结构化”以及“结构化的应用场景”四个方面,为你提供一个全面且可操作的解析。
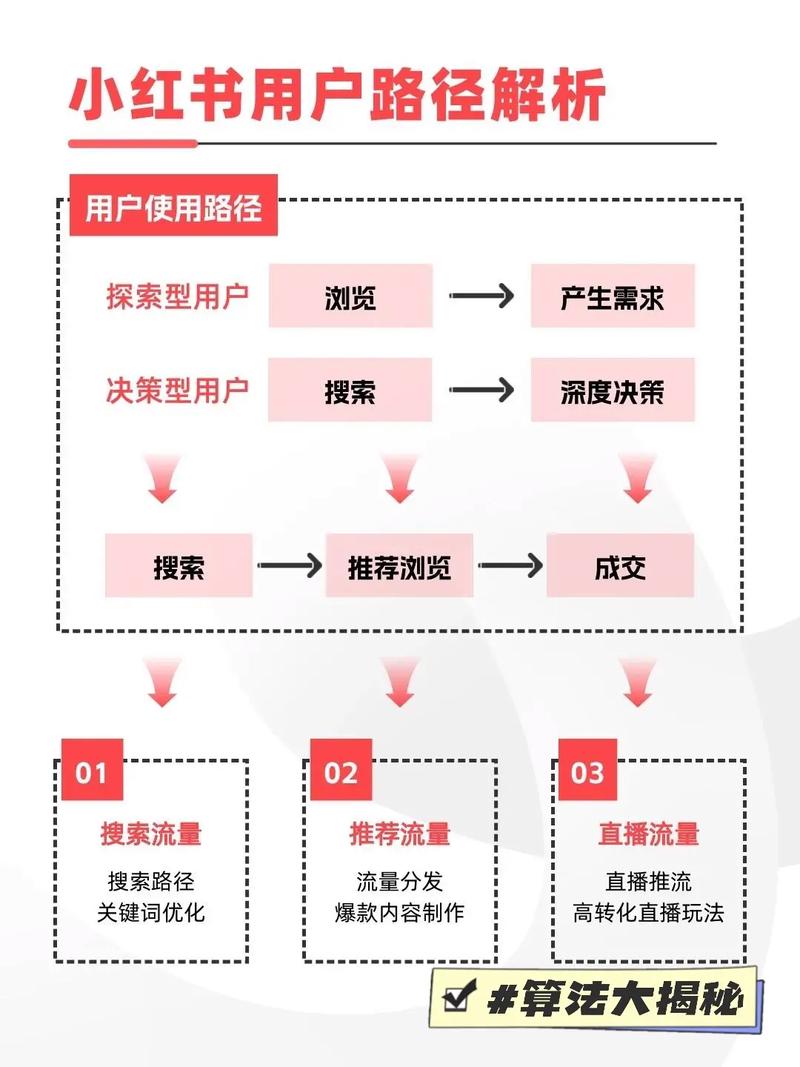
为什么小红书数据需要结构化?
小红书作为一个以UGC(用户生成内容)为核心的社区,其原始数据(笔记标题、正文、图片、评论等)是非结构化或半结构化的,直接处理这些数据效率低下,价值难以挖掘,数据结构化的目的在于:
- 提升数据可读性与可用性:将文本、图片等复杂信息转化为计算机可以理解和处理的格式(如JSON、数据库表),方便进行存储、查询和分析。
- 实现精准内容分析:通过结构化,我们可以量化笔记的表现,分析哪些标题、标签、图片、发布时间更受欢迎,从而指导内容创作。
- 赋能商业决策:品牌方和商家可以通过结构化数据,洞察市场趋势、分析竞品动态、评估营销效果,实现数据驱动的运营。
- 构建推荐与搜索系统:小红书自身的推荐算法和搜索功能,其底层逻辑就是建立在将用户行为(点赞、收藏、搜索词)和内容属性(标题、标签、话题)进行结构化,并进行匹配计算的基础之上。
- 自动化与智能化:结构化是实现自动化内容审核、智能客服、舆情监控等高级应用的前提。
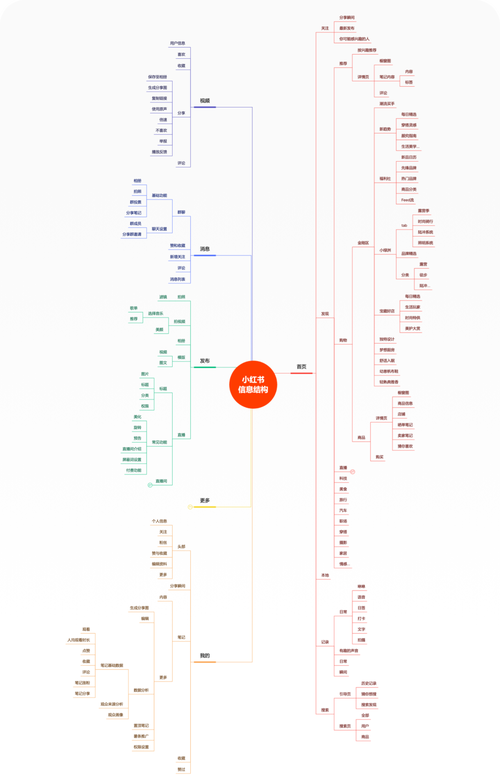
结构化的对象:小红书的核心数据源
要对小红书数据进行结构化,首先要明确我们要处理哪些数据,主要可以分为以下几类:
| 数据类别 | 结构化方向 | |
|---|---|---|
| - - - 图片/视频 - 标签 (#) - 话题 (@) - 发布位置 - 发布时间 |
- 文本分析:提取关键词、情感倾向、实体识别(如品牌名、产品名)。 - 视觉分析:识别图片中的物体、场景、颜色、风格(通过AI模型)。 - 标签/话题分类:将标签归入预定义的品类。 - 时间/地点格式化:转化为标准时间戳和地理坐标。 |
|
| 用户信息 | - 用户名 - 个人简介 - 头像 - 粉丝数/关注数 - 笔记数 - 认证信息 |
- 用户画像构建:根据简介和内容,给用户打上兴趣标签(如“美妆爱好者”、“健身达人”)。 - 用户分层:根据粉丝数、互动率等,将用户分为KOL、KOC、普通用户等。 |
| 互动数据 | - 点赞数 - 收藏数 - 评论数 - 分享数 - |
- 互动指标量化:直接作为数值字段存储。 - 评论情感分析:分析评论是正面、负面还是中性。 |
| 商品数据 | - - 价格 - 品牌 - 所属店铺 - 商品链接 |
- 商品信息提取:自动识别品牌、价格区间、商品类别。 - 链接规范化。 |
| 搜索与广告数据 | - 搜索关键词 - 广告投放信息(如人群、出价、点击率) |
- 关键词聚类与分析:发现热门搜索词和用户意图。 - 广告效果归因分析。 |
如何进行小红书数据结构化?(方法论与工具)
数据结构化是一个系统工程,通常包含以下几个步骤:
步骤1:数据采集
这是第一步,没有数据,一切都无从谈起。
- 官方API:小红书开放平台提供了一些API接口,可以合规地获取部分公开数据,这是最推荐的方式,但申请门槛较高,且有调用限制。
- 网络爬虫:通过编写爬虫程序(如使用Python的Scrapy, Requests, BeautifulSoup等库)抓取小红书网页或App的数据。注意:此方法需要遵守
robots.txt协议,并注意数据抓取的频率和方式,避免对平台造成过大压力,同时要关注相关法律法规。 - 第三方数据服务商:市场上存在一些专业的社交媒体数据服务商,他们已经完成了数据采集和初步结构化,可以直接购买API或数据包,成本较高,但省时省力。
步骤2:数据清洗与预处理
原始数据通常包含大量“脏数据”,需要清洗。
- 去重:去除重复的笔记或评论。
- 去噪:去除无意义的符号、表情、HTML标签等。
- 格式统一:统一日期格式(如
YYYY-MM-DD)、数字格式等。 - 处理缺失值:对缺失的字段(如位置)进行填充或标记。
步骤3:核心结构化处理
这是最关键的一步,将非结构化数据转化为结构化信息。
A. 文本结构化(NLP技术)
- 关键词提取:
- 方法:TF-IDF, TextRank等算法。
- 应用:从一篇“OOTD穿搭分享”的笔记中,自动提取出“碎花裙”、“法式”、“显瘦”、“白色”等核心关键词。
- 实体识别:
- 方法:基于规则或NLP模型(如BERT)。
- 应用:从笔记“今天用了YSL的小黑条,颜色绝了!”中,识别出品牌实体“YSL”和产品实体“小黑条”。
- 情感分析:
- 方法:训练或使用现成的情感分析模型。
- 应用:分析评论“这个也太好用了吧!”为正面情感,“物流太慢了”为负面情感。
- 主题/意图分类:
- 方法:有监督学习(需要标注数据训练模型)或无监督学习(如LDA主题模型)。
- 应用:将所有笔记自动分类到“美妆护肤”、“美食探店”、“旅游攻略”等预设的或自动生成的主题下。
B. 图像/视频结构化(CV技术)
- 物体识别:
- 方法:使用预训练的深度学习模型(如ResNet, YOLO)。
- 应用:识别图片中的“口红”、“包包”、“咖啡”、“海景”等物体。
- 场景识别:
- 方法:图像分类模型。
- 应用:判断图片场景是“室内”、“户外”、“餐厅”、“商场”。
- OCR(光学字符识别):
- 方法:使用Tesseract, PaddleOCR等库。
- 应用:识别图片中的文字,如海报上的活动信息、商品包装上的文字。
C. 元数据结构化
这部分相对简单,主要是对平台已有的半结构化信息进行规范化处理。
- 将后的内容提取出来,并去除号。
- 话题:将后的内容提取出来。
- 时间/地点:使用正则表达式或专门的库,将发布时间解析为时间戳,将地点信息解析为标准地名。
步骤4:数据存储
结构化后的数据需要存储起来以便后续使用。
- 关系型数据库:如MySQL, PostgreSQL,适合存储结构清晰、关系固定的数据,如用户信息、笔记的元数据(标题、发布时间、互动数)。
- NoSQL数据库:如MongoDB,适合存储非结构化或半结构化数据,如每篇笔记的详细文本、提取的关键词列表、图片识别结果等,因为它们的模式不固定。
- 数据仓库:如Snowflake, Google BigQuery,当数据量巨大,需要做复杂的商业智能分析和报表时,数据仓库是更好的选择。
结构化数据的应用场景举例
完成数据结构化后,其价值才能被释放。
-
内容创作者/MCN机构:
- 竞品分析:监控竞品账号的笔记,分析其高赞笔记的标题、标签、发布时间规律,优化自己的内容策略。
- 热点追踪:通过分析高频出现的关键词和话题,快速捕捉平台热点,进行内容创作。
- 效果复盘:量化分析不同类型内容的互动率,找到最适合自己的内容方向。
-
品牌方/商家:
- 舆情监控:实时监控品牌相关关键词的情感倾向,及时发现并处理负面舆情。
- KOL/KOC筛选:根据结构化数据(粉丝画像、互动率、内容垂直度、历史合作效果)建立筛选模型,高效找到最匹配的达人。
- 市场趋势洞察:分析某个品类(如“防晒霜”)下的用户讨论焦点、热门成分、价格区间,指导产品开发和营销策略。
-
平台方/数据服务商:
- 推荐系统优化:将用户兴趣(结构化的行为数据)和内容标签(结构化的内容数据)进行精准匹配,提升推荐点击率和用户粘性。
- 搜索排序优化:理解用户的搜索意图(结构化的查询词),结合内容的相关性、权威性、时效性进行排序。
- 商业化广告投放:根据用户的结构化画像,进行精准的广告定向投放,提升广告ROI。
小红书数据结构化是一个将“看得懂”的社区内容转化为“机器能懂”的数据资产的过程,它始于数据采集,核心是NLP/CV技术处理,终于数据存储与应用。
对于个人或小团队,可以从简单的Excel表格或JSON文件开始,手动或用简单的脚本对少量笔记进行结构化练习,逐步深入,对于企业级应用,则需要构建一套完整的数据采集、处理、存储和分析的数据平台。
掌握数据结构化的能力,意味着你不再仅仅是小红书的“浏览者”,而是能够洞察其内在规律的“分析师”和“操盘手”,这在当今的数字营销和内容运营领域,无疑是一项极具竞争力的核心技能。
作者:99ANYc3cd6本文地址:https://www.chumoping.net/post/14322.html发布于 01-14
文章转载或复制请以超链接形式并注明出处初梦运营网







